Cassandra. Часть 5. Compaction
Главной причиной высокой скорости записи Cassandra является то, что запись данных последовательна. Данные попадают в оперативную память, сортируются в memtable, а затем блоком, в виде SSTable сбрасываются на диск. Именно благодаря такому подходу, Cassandra приближается тому, что ее производительность при сохранении равна скорости записи диска.
А что же с чтением? То, что Cassandra данные хранятся в отсортированном виде, конечно, конечно позволяет быстро находить нужную информацию в SSTable. Но как быть если SSTable у одной таблицы слишком много? Издержки на поиск среди этих них могут быть слишком велики. Причем, догадаться в какой именно SSTable лежат необходимые нам данные – нет никакой возможности,. Нужно заглядывать в каждую SSTable.
Что если объединить все эти SSTable в один большой? Тогда, чтобы найти запись, нужно будет прочитать всего 1 файл. Т.е. достаточно лишь один раз позиционировать головку диска в нужное место, а затем лишь непрерывно читать. Следовательно, для операций чтения, эффективнее хранить как можно меньше SSTable.
Именно этим и занимается операция compaction. Compaction - это процесс объединения нескольких SSTable в одну, данные внутри которой вновь SSTable сортируется, а также создается новый индекс и bloom-filter (у каждой SSTable есть Данные, Индекс и Фильтр).
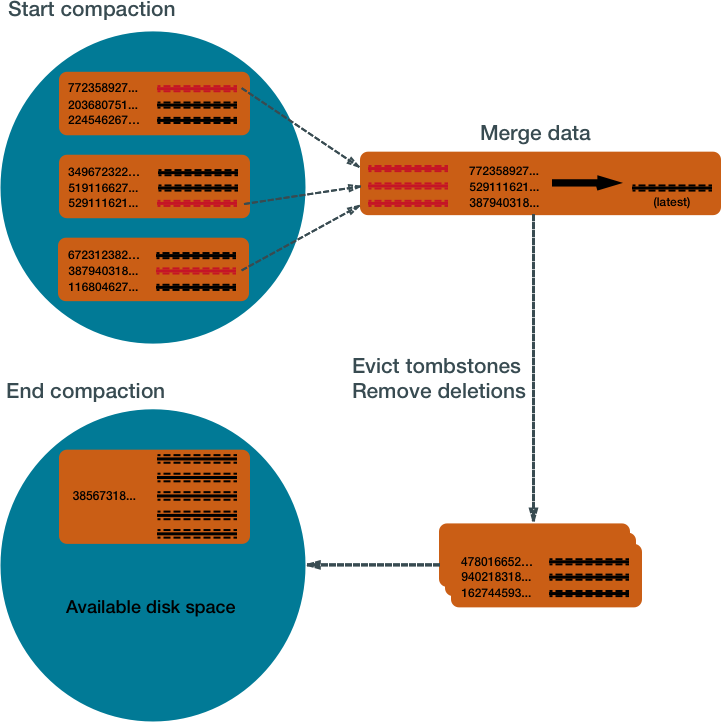
Алгоритм работы compaction
Дополнительным достоинством операции compaction является освобождение места на диске, т.к. при создании новой SSTable, можно отбросить удаленные записи. Операция очень сильно напоминает ребилдинг в реляционных БД. Основное отличие в том, что compaction выполняется автоматически и запускать его вручную нет необходимости.
Недостатком же является существенное влияние на систему I/O. Также на диске должно быть достаточно свободного места, на объединие двух SSTable по 1Гб, необходимо дополнительно 2Гб дополнительного места.
В Cassandra существуют различные алгоритмы compaction:
- SizeTieredCompactionStrategy (STCS) - стратегия по умолчанию, рекомендуется для таблиц с высокой нагрузкой на запись
- LeveledCompactionStrategy (LCS) - рекомендуется для таблиц с большим количеством операций чтения
- DateTieredCompactionStrategy (DTCS) - предназначена для данных основе времени
Ссылки
- http://docs.datastax.com/en/cassandra/3.0/cassandra/dml/dmlHowDataWritten.html