Cassandra. Часть 1. Проектирование данных
Cassandra представляет собой гибрид между key-value хранилищем и колоночно-ориентированной БД. Если к key-value хранилищам она относится за счет того, что у каждой записи обязательно есть первичный ключ (key) и связанное с ним значение (value), то к семейству колоночных - потому, что значение (value) может состоять из большого количества столбцов.
Такой гибрид накладывает ряд особенностей, который и будут рассмотрены ниже.
Отсутствие join
В Кассандре нет джойнов. Чаще всего, это ограничение обходится с помощью денормализации данных по дополнительным таблицам либо с помощью выполнения псевдо-джойнов на клиенте. Второй вариант работает медленнее, поэтому встречается реже.
Отсутствие внешних ключей
В Кассандре нет способа связывать сущности из разных таблиц между собой, как например, это сделано в реляционных базах с помощью внешних ключей. Как следствие отсутствуют такие операции как каскадное удаление.
Денормализация
Сама по себе денормализация обладает одним достоинством, в отличие от обычного подход. Ее удобно использовать для хранения исторических данных, которые ни при каких обстоятельствах не должны изменяться. В качестве примера можно привести хранение покупок клиента со ссылками на товар. Т.к. цена товара меняется с течением времени, чтобы получить стоимость каждого товара на момент приобретения, нужно отдельно хранить цену товара. При использовании подхода с денормализацией, можно в таблице с покупками хранить полностью объект товара. При этом текущий товар можно изменять любым образом и даже удалять и это никак не повлияет на историю покупок клиента.
Запрос первичны
В реляционных БД проектирование выполняется в бизнес-сущностях. Сначало создаются таблицы, каждая из которых описывает сущность, при этом мы не задумываемся об sql-запросах на этом этапе. Это происходит потому, что мы знаем, что всегда можем использовать join (либо вложенные select’ы), чтобы получить получить данные из нескольких таблиц!
В Кассандре используется другой подход. При проектирование, нужно учитывать, что запрос должен получить за один раз все данные из одной таблицы (т.к. нет join). Поэтому сначала проектируются все возможные запросы, а затем под них создаются таблицы. Таким образом в Кассандре создание структуры БД начинается с определения запросов.
Оптимальное хранение
В реляционных базах редко можно встретить рекомендации к структуре БД для оптимального хранения и чтения данных. Чаще всего никто не заботится об этом. В распределенных системах дело обстоит иначе, т.к. данные располагаются на нескольких узлах, более высокую производительно будет демонстировать тот запрос, который отдает данные с одной ноды. Таким образом, желательно располагать данные так, чтобы данные возвращались из одной ноды. Хотя это и не обязательное требование, а в некоторых случаях и невозможное (например подсчет общего количество строк в таблице), все же нужно помнить об этом.
Паттерн Wide rows
Есть различные способы хранения данных в таблице, рассмотрим 2 подхода:
Skinny rows - на каждой строке размещается новый объект, а количество столбцов равно количеству свойств объекта. Такой подход используется в реляционной модели.
Wide rows – в одной строке размещается несколько объектов сгруппированных по какому-то признаку. Именно этот подход рекомендуется использовать в Кассандре.
Например необходимо хранить данные мониторинга системы. Чтобы не хранить каждое событие в отдельной строке, необходимо выделить признак группировки событий. В качестве такого признака возьмем временной интервал «день» и объединими события в течение одного дня в один список. Именно это список будет храниться в одной строке. Теперь, когда мы попросим Кассандру вернуть нам события мониторинга за один день, мы получим все события за этот день последовательным (а значит и самым быстрым) чтением с диска.
Еще одним достоинством такого подхода является возможность фильтрации данных. Благодаря тому, что Кассандра физически хранит колонки в упорядоченном виде, можно быстро выполнить фильтрацию (range scan) в строке.
Особенности поиска Кассандры
- Кассандра быстро находит строки (благодаря хешу на первичный ключ)
- Кассандра быстро выбирает диапазон столбцов (range scan по кластерным ключам)
- Кассандра не сканирует (range scans) строки.
Материализованные представления
Денормализовать данные можно двумя способами, первый – это самостоятельно сохранять данный сразу в несколько таблиц. Второй способ – использовать материализованные представления (МП).
МП представляют собой специальную таблицу которая сама заботится об обновлении своих данных. Она создает на основе существующей таблицы и использует эту таблицу в качестве источника данных. Обновление таблицы-источника, влечет за собой автоматическое обновление связанных с ней МП. По сравнению с ручным подходом, МП демонстрируют более высокую производительность за счет пакетных операций.
Есть и ограничения при создании МП. Первичный ключ МП должен совпадать с первичным ключом таблицы-источника. Это ограничение позволяет Кассандре избежать дорогостоящего объединения нескольких строк в одну для последующей вставки в МП. Наиболее распространенный случай использования МП – использование первичных ключей в качестве кластерных и выделение нового первичного ключа.
В таблице ниже reservations_by_hotel_date - таблица источник, reservations_by_confimation – МП.
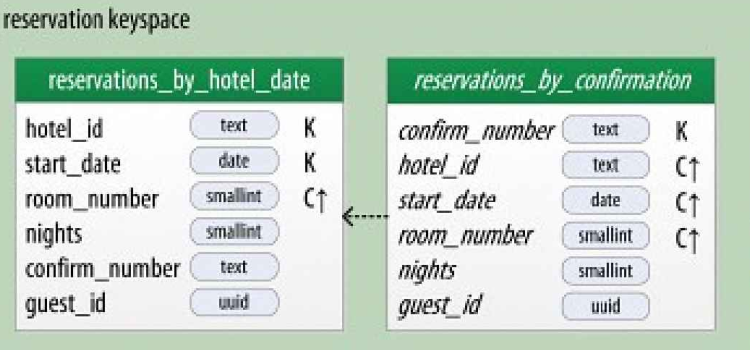
В Кассандре версии 3.0 есть неприятные ограничения при использовании МП. Одно из них связано с невозможностью использовать несколько первичных ключей в МП https://issues.apache.org/jira/browse/CASSANDRA-9928, второе – с отсутствием агрегации https://issues.apache.org/jira/browse/CASSANDRA-9778.
Источники
- http://grokbase.com/t/cassandra/user/141z5z8cvy/ultra-wide-row-anti-pattern