Алгоритм consistant hashing & virtual nodes
Cassandra, как и другие NoSQL key-value хранилища, имеет распределенную архитектуру и хранит данные на нескольких серверах. При выполнении записи, БД должна однозначно орпеделять ноду, на которую нужно сохранить данные. Такое же требование касается и чтения, БД, получив ключ документа, должна определить к какой ноде обращаться, чтобы не искать по всем нодам. Поэтому необходим алгоритм выбора нод для чтения/записи, который получивключ записи (key) и вернет адрес ноды. Для того, чтобы этот алгоритм можно было использовать в промышленном решении, определим для него несколько условий:
- Высокая скорость работы, не меньше 10.000 операций в секунду.
Операция опеределения ноды очень частая операция, поэтому нельзя в работе подгружать какие-то данные с диска/БД или обращаться по сети в сторонний сервис. - Алгоритм должен одинаково работать на всех нодах.
Запросы на получение данных приходят на все ноды (в materless архитектуре клиент может подключиться к любой ноде), и они самостоятельно должны прийти к верному решению о расположении данных. - При добавлении/удалении нод из кластера не должно быть избыточного перемещения данных.
При добавлении ноды должны перемещаться только данные, необходимые для ее заполнения. Аналогично, при удалении ноды, только ее данные должны распределиться между остальными нодами. Дополнительных, паразитных перемещений данных не должно быть.
Итак, наша задача описать функцию, которая будет получать ключ и возвращать сервер с расположением документа:
F(key) = server
Hashing algorithm
Наиболее очевидный вариант, взять хеш от ключа, разделить на количество серверов и взять остаток от деления. Полученное число использовать как индекс в массиве с адресами серверов:
servers = [‘server1’, ‘server2’, ‘server3’]
server_for_key(key) = servers[hash(key) % servers.length]
Функции хеширования имеет ограниченную вариативность результатов. Например, у алгоритма murmur, результаты лежат в интервале от -2^63 до 2^63. Графически интервал можно представить не в виде линии, в виде кольца, точки на окружности которого будут соответствовать результатам хеш-функции. Такое кольцо называется token ring.
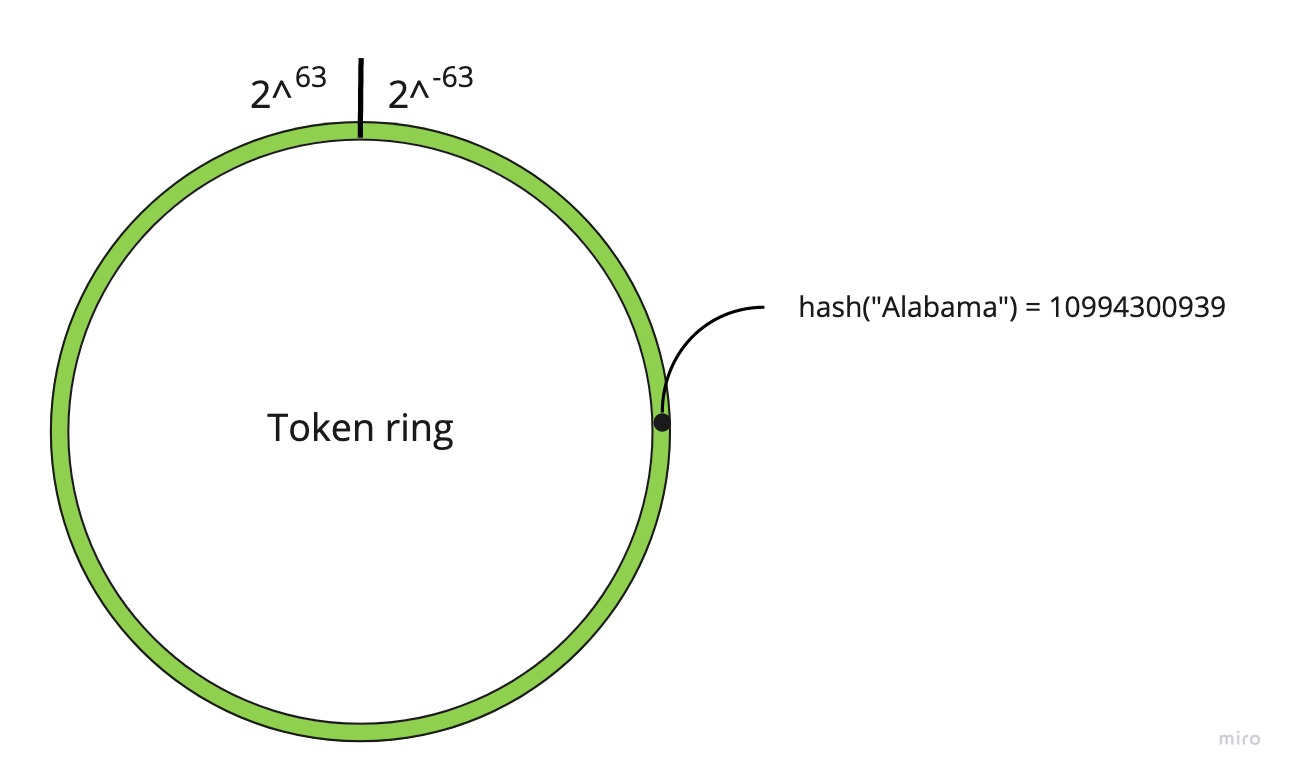
Недостатки
Однако в этом случае, при добавлении/удалении узла потребуется перераспределить большое количество данных. Например, при добавлении в кластер из 4-ех узлов нового узла, 80% данных поменяют свой сервер. См. Проблемы при работе с кэшем и способы их решения[6]
Сonstistancy hashing algorithm
Согласованное хеширование (constistancy hashing) позволяет избежать описанной выше проблемы. Работает оно следующим образом:
- Определяются фиксированные имена нод, чащего всего это ip-адреса или их hostname.
- К каждому из них применяется функция хеширования.
- Полученные хеши помещаются на token ring, разбивая его на интервалы. За каждый интервал отвечает собственная нода.
- При поиске узла, от ключа берется хеш, и опеределяется интервал в который он попадает. Так как у каждого интервала есть “хозяин”, сервер который им владеет, по нему и определяется искомая нода.
Важно. Имена нод (шаг 1), на основе которых рассчитывается интервал владения не должны изменяться.
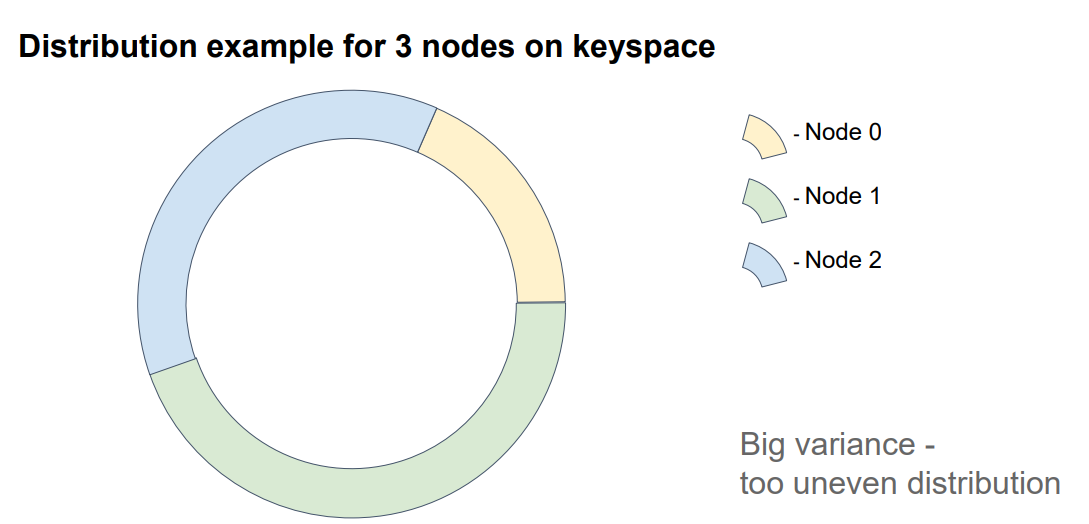
Перестроение данных
При добавлении ноды, ее хеш попадает в чей-то интервал и разделяет его. И эта нода делится собственными данными, с вновь присоединившейся.
Удаление ноды запускает обратный процесс, в котором интервалы объединяются.
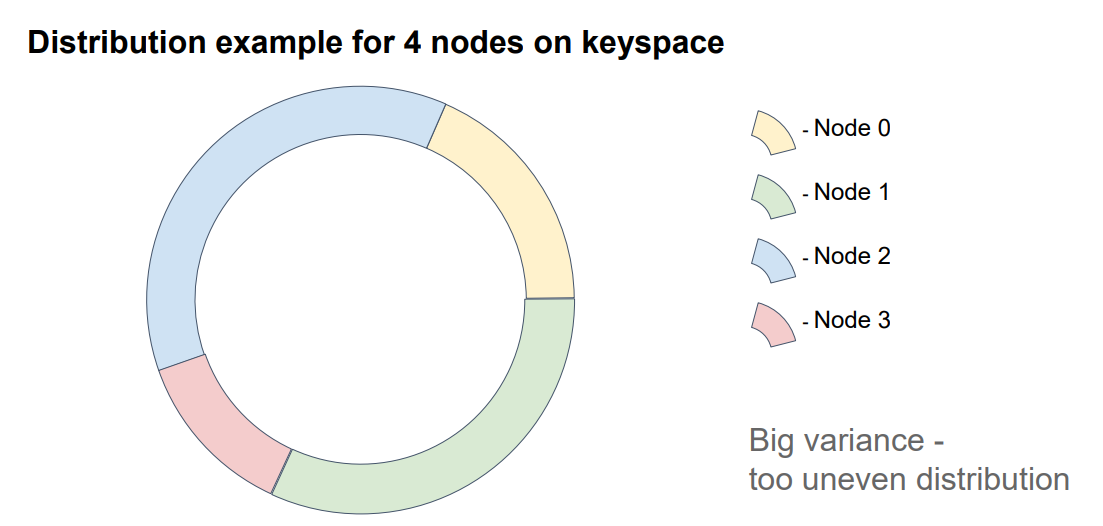
Недостатки
Минус данного подхода в том, что размер интервалов зависит от результата хеш-функции и никак не контроллируются, и они могут получится либо очень большие, либо очень маленькие.
Так при добавлении четвертой ноды в кластер, видно, что ей достался наименьший интервал:
Сonstistancy hashing algorithm with virtual nodes
Этот подход использует данные исследования[7], согласно которому, при увеличении количества серверов распределение будет нормализовываться. То есть размеры интервалов будут усредняться, решая проблему предыдущего алгоритма. Для 200 серверов стандартное отклонение составляет около 5%, а для 100 узлов около 10% от среднего.
Идея этого алгоритма заключается в использовании виртуальных нод, вместо реальных серверов. Алгоритм помещения их на интервал хеш-функции такой же как в алгоритме согласованного хеширования. Однако дополнительно устанавливается связь между виртуальной нодой и физической нодой (физической ноде будет соответствовать несколько виртуальных). Таким образом, рассчитав на какую виртуальную ноду попадает ключ, с помощью связи определяется физическая нода.
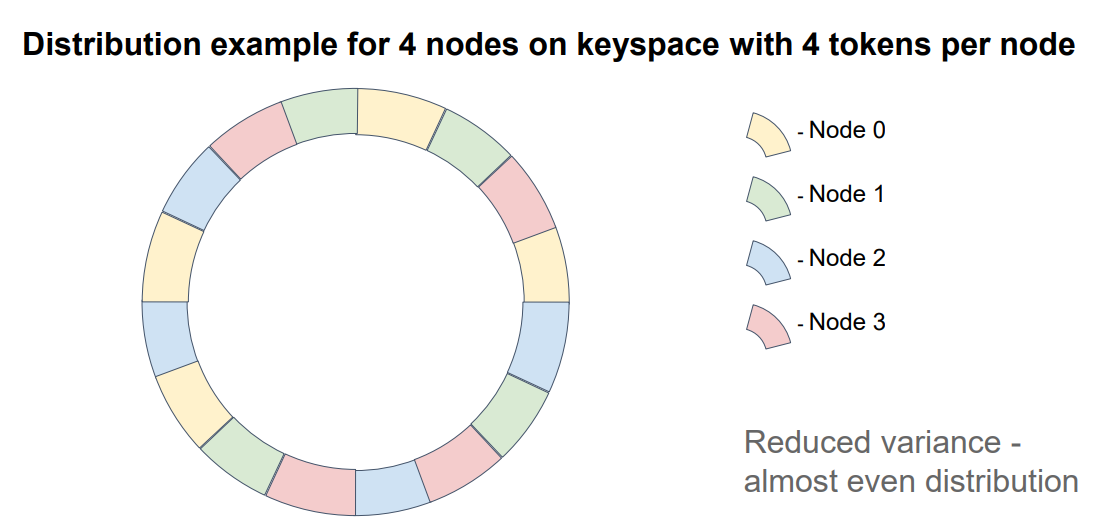
Настройки в Cassandra
За число виртуальных нод отвечает параметр num_tokens в файле cassandra.yaml и по умолчанию он равен 256. То есть, если кластер состоит из 1 ноды, token ring будет поделен на 256 интервалов, если из 2 - на 512 и т.д. Это обеспечивает хорошее распределение, однако серьезно влияет на производительность: растет число SSTable, дольше выполняется repair, увеличивается использование CPU.
- Компания thelastpickle.com, специализирующаяся на OpenSource Cassandra рекомендуют установить num_tokens=4.
- Datastax, рекомендует устанавливать это число равное 8.
Изменение количества виртуальных нод в созданном кластере запрещено, так как это приведет полному перераспределению данных. Поэтому важно задать их количество ДО инициализации кластера.
Ссылки
- https://www.datastax.com/dev/blog/virtual-nodes-in-cassandra-1-2
- https://stackoverflow.com/questions/38423888/significance-of-vnodes-in-cassandra
- http://thelastpickle.com/blog/2019/01/30/new-cluster-recommendations.html
- https://danielparker.me/cassandra/vnodes/tokens/increasing-vnodes-cassandra/
- https://www.datastax.com/dev/blog/token-allocation-algorithm
- https://habr.com/ru/company/badoo/blog/352186
- https://tom-e-white.com/2007/11/consistent-hashing.html